
3B超越DeepSeek,大模型终于理解时间了,Time-R1一统过去/未来/生成 小模型的“屠榜时刻”!时间是我们日常生活中最基础的概念。然而,对于大语言模型(LLM)来说,尽管它们能够写诗作画、通晓古今,但在真正理解和运用时间概念时却常常显得力不从心。


这个技术短板源于大模型的底层设计:训练语料库是静态的,存在知识截断时间;在按非时间顺序的语料训练过程中,跨越不同时期的时间信息是同时处理的,不像人类逐步接收知识,这阻碍了在事件与其对应时间之间建立可靠的逻辑映射。现有的方案如时间对齐、外部知识库等,如同「打补丁」,未能实现「理解-预测-生成」的全链路突破。
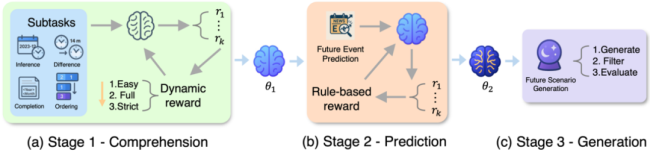
最近,伊利诺伊大学香槟分校的研究人员发布了一份突破性成果Time-R1,基于一个仅3B的小模型,通过精心设计的三阶段课程强化学习,实现了理解过去、预测未来甚至创造性生成的大一统。该框架的核心创新在于其精心设计的动态的、基于规则的奖励机制,像一位经验丰富的导师,逐步引导模型掌握时间的奥秘。
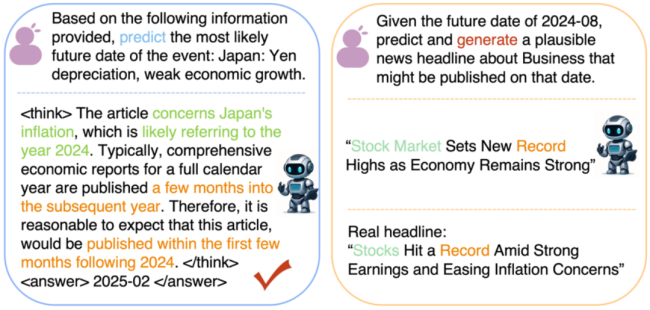
Time-R1的具体实现由三个阶段组成: – 阶段1通过四个时间子任务进行强化微调,建立时间观念的基本理解; – 阶段2在阶段1的基础上进一步使用知识截止时间后以及合成的数据来训练,锻炼预测未来的能力; – 第3阶段直接进行创造性未来情景的生成。
第一阶段通过在四大特训任务上的强化微调,建立事件与时间的精准映射:时间戳推理,时间差计算,事件排序,时间实体补全。第二阶段在严格隔离未来数据的前提下,在阶段一得到的模型checkpoint基础上继续强化微调,让模型从历史规律中自主推演趋势。第三阶段无需额外训练,直接生成指定未来时间下合理的推演未来场景。
Time-R1的成功很大程度上归功于研究人员为每个子任务量身定制的极其细致的奖励函数。这套奖励机制的代码总行数超过了1200行,每一个设计细节都是在模型试图「钻空子」、寻找捷径时针对性地提出「反制措施」,是无数次实验和迭代的结晶。

通用奖惩设计包括格式遵循奖励、标签结构奖励、长度与重复惩罚等。特定任务的精准「标尺」则针对每个任务的特性进行设计,如时间戳推断、时间差估计、事件排序、掩码时间实体补全等。
为了应对从零开始微调LLM进行专门时间任务时的「冷启动」挑战,并培养模型在难题上的稳健表现,研究团队在第一阶段引入了动态奖励机制。根据任务难度和训练进程,动态调整日期准确性奖励部分中的衰减系数α。
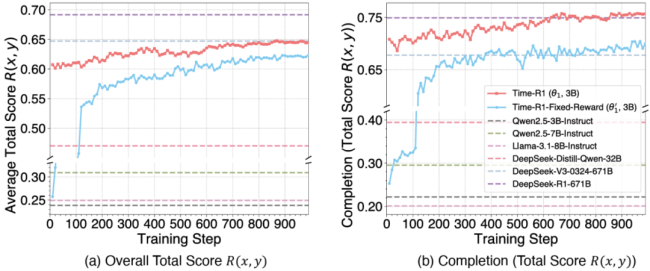
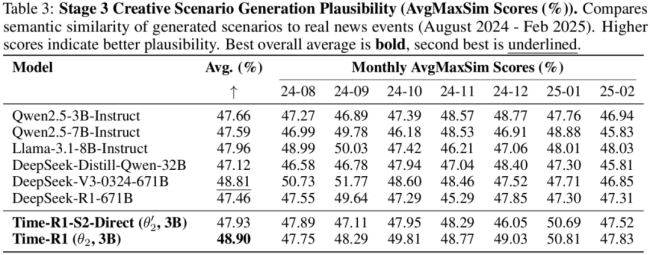
通过上述精心设计,Time-R1在第一阶段取得了令人瞩目的成绩。最新实验结果显示,Time-R1 (3B) 在基础时间理解任务上已经成功超越了参数量200多倍的DeepSeek-V3-0324模型。在有了基础时间推理能力后,继续训练的Time-R1在未来事件时间预测上持续优于大多数基线模型。在没有任何微调的情况下,创造性场景生成任务中,Time-R1同样取得了最佳的平均最大相似度得分,展现了强大的泛化能力。
Time-R1通过一种新颖且精心设计的三阶段强化学习课程和动态奖励系统,实现了全面的时间推理能力——涵盖理解、预测和创造性生成,碾压671B巨无霸模型。这一成功直接解决了大模型领域的一个重要痛点,并证明了先进的渐进式强化学习方法能够使更小、更高效的模型实现卓越的时间性能,为实现具有巨大应用潜力的、真正具备时间意识的人工智能提供了一条实用且可扩展的路径。
研究团队还实现了全面开源,发布了Time-Bench数据集、完整训练代码以及各阶段模型检查点,积极促进下一步的研究和发展。
文章来源于网络。发布者:光明参考网,转转请注明出处:https://www.gmrb1949.com/14933.html